最近一个项目进行2.0版本升级。2.0版本部署到所有的线上机器后,发现网站访问速度变的很慢。为了不影响用户体验,紧急进行版本回滚,然后进行问题查找。
分析
首先查看php的日志,没有发现有用的线索。
然后看了下mysql db的监控情况。如下图:
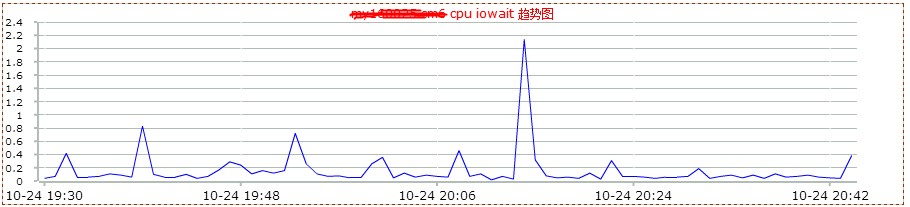
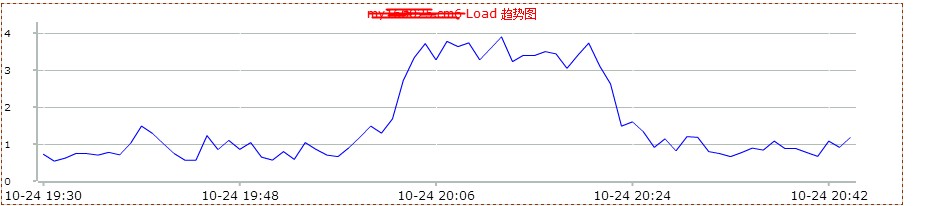
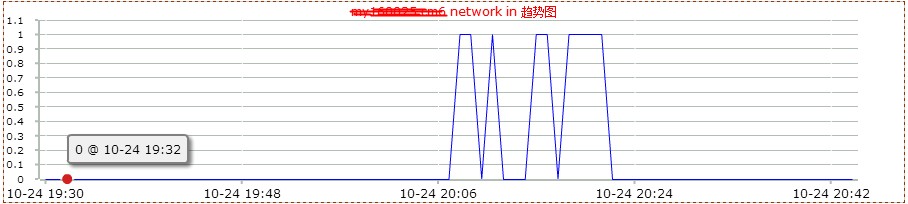
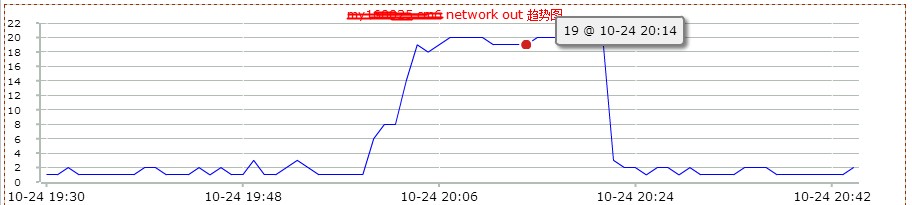
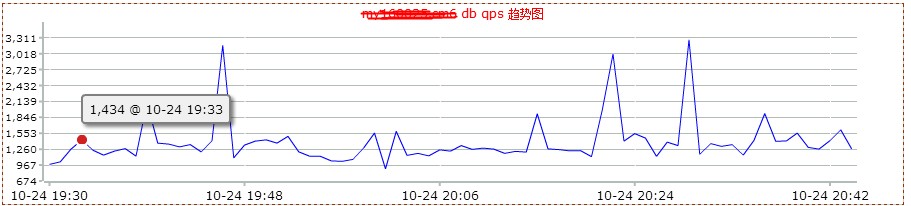
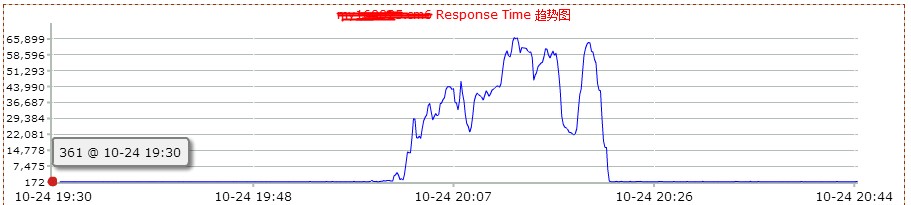
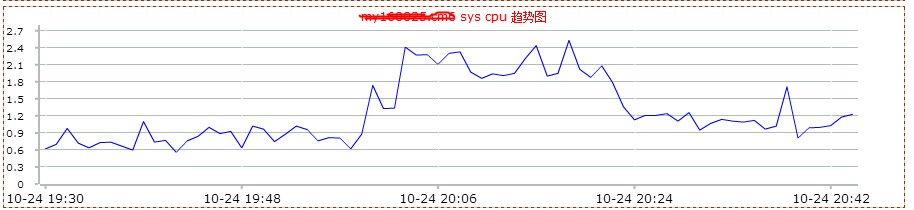
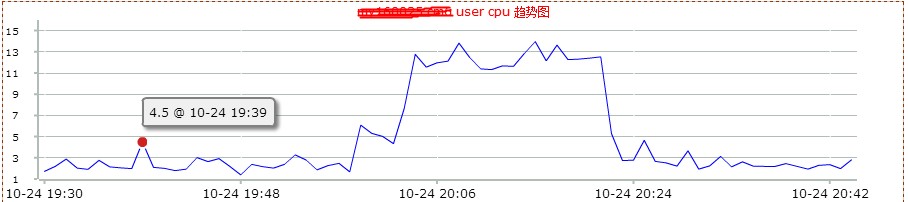
2.0版本是在20点左右上线,20点20分左右回滚。从上图,可以看到2.0版本上线后,数据库服务器的网络io明显增高。这说明,不仅查询的次数增多了,而且返回的数据量也增大了很多。看来网站变慢很可能和mysql数据库查询有关。和db负责人沟通,让其查看是否有sql的满查询。但是反馈很让人意外。他查看慢查询日志后,没有发现执行效率有问题的sql。
在web服务器上,使用strace对php进程的执行情况做了进一步的跟踪。发现有一条sql (show status)语句频繁执行。这条语句的具体执行情况如下:
看这条show status语句的执行情况。
A. 从发起sql查询,到可以读取结果大概花费了0.405毫秒。从1382678984.106491开始向mysql服务器发送查询请求。从1382678984.106896就已经完成了sql查询,并且可以读取数据了。可见这条sql语句的查询速度还是很快的。
B. 从发起sql查询,到读取完所有数据大概消耗了3毫秒。这条sql语句返回的数据大概10k左右,查询结果分两次才读取完毕。
C. 这条sql语句每秒执行了240次计算,这样每秒大概要有3*240 = 720毫秒消耗在这条sql语句中。这样1秒中有72%的时间消耗在这条sql查询上。这样就导致要多花费3.5倍的时间进行数据库操作。大家都直到web站点的瓶颈多数在数据库查询。
这样看来,很有可能就是这条sql语句导致的网站响应速度变慢。那为什么会每秒有这么多次查询?在2.0代码中增加了重试机制,即发现数据库连接有问题的时候,进行数据库重连。在设计重试机制时逻辑有问题,是每次进行数据库操作前都进行一次show status的查询,如果查询失败就进行数据库重新建立连接。
总结
1.不要因为某条sql的执行效率高就忽视。甚至肆无忌惮的使用。
2.不仅要注意sql的执行效率,还要特别注意返回数据量比较大的sql。否则过大的数据量返回,会给数据库造成很大的网络io压力。进而会导致load过高等一系列的反应。
3.合理的机制和策略很重要。不要滥用sql查询。
补充
本文原发布在阿里内网“阿里云计算”圈中,引起一些评论。因此在原文的基础上结合评论整理后发在本圈。
在原文评论中提到了select查询时,*符号的使用。我感觉非特殊必要,建议不要在select查询中使用*符号。如:select * from feed. 原因有以下几点:
1.当你仅需要表中部分字段中的内容时,必然会导致资源浪费。如,多余的数据必然会导致更多的网络io(大家直到io是很耗资源的一个操作)。多于数据在网络中传输会导致网络带宽的浪费。
2.不利于后期维护。作为web程序对应数据表的更改是常事。如表中某个字段名修改了,如果使用*的情况下,必须把所有引用此字段的地方的代码都要做相应修改。如果是通过select field from feed这样指定字段名查询数据。当field字段更名为new_field时,只要在select中使用AS 关键字即可。select new_field AS field from feed. 这样改动比较小。
另外,有两点需要注意。不过这些和数据库的SERVER端实现有关。
1.如果使用*的时候,可能会导致从*到表中字段名columns的转换。会造成一些时间浪费。2.在所需要的列正好都有索引时,可能数据直接读取索引。这样可以更少的磁盘io,从而提高效率。
技术交流

原文链接:小心!高效率的sql查询,它也会导致网站响应变慢,转载请注明来源!


以后编码得注意这个了。。。
[ali吓] 很好啊,顶一下\\\
[ali吓] 很好啊,顶一下\\\
对于使用select *的问题,实话说,如果使用工程化的ORM等机制,几乎很难避免这个东西,事情总是需要权衡的。。。
说的不错。没有完全的合适。凡是要权衡。重要的时权衡的能力。
爱奇趣网http://www.iqiqu.net/? 路过留个言!
网站不错很漂亮,欢迎互访!
路过,留个脚印,网站很棒!
不错学习了,谢谢分享! http://www.xevip.cn
这个240次 哪里看的出来